How Do Coding Agents Spend Your Money?
Analyzing and Predicting Token Consumptions in Agentic Coding Tasks
Can You Guess the Token Cost?
Test your intuition about agent token consumption
Challenge yourself to predict token consumption and costs for real coding agent tasks!
Play the Guessing GameAbstract
Wide adoption of AI agents in complex human workflows drives rapid growth of LLM token consumption. We use "token consumption" to refer to both input and output tokens used by LLM agents. When agents are deployed on tasks that can require a large amount of tokens, three questions naturally arise: (1) Where do AI Agents spend the tokens? (2) What models are more token efficient? (3) Can LLMs anticipate the token usage before task execution?
In this paper, we present the first quantitative study of token consumption patterns in agentic coding. We analyze trajectories from eight frontier LLMs on a widely used coding benchmark (SWE-Bench) and evaluate models' ability to predict their own token costs before task execution. We find that: (1) agentic tasks are uniquely expensive: they consume substantially more tokens and are correspondingly more expensive than code reasoning and code chat, with input tokens being the key driver of the overall cost, instead of output tokens. (2) Token usage is highly variable and inherently stochastic: runs on the same task can differ by up to 30× in total tokens, and higher token usage does not translate to higher accuracy; instead, accuracy often peaks at intermediate cost and degrades at higher cost. (3) Model-to-model token efficiency is governed more by model differences than by human-labeled task difficulty, and difficulty labels only weakly align with actual resource expenditure. (4) Finally, frontier models fail to accurately predict their token usage (with weak-to-moderate correlations, up to 0.39), and systematically underestimate the real token costs. Our study reveals important insights regarding the economics of AI agents and can inspire new studies in this direction.
Key Findings
1) Agentic coding is uniquely expensive
Comparison of three coding paradigms: Code Reasoning (single-turn problem solving without tool interaction), Code Chat (multi-turn dialogue with moderate response expansion), and Coding Agent (tool-augmented, repository-level exploration with long-horizon context). Agentic coding tasks consume substantially more tokens and incur significantly higher monetary costs than the other two paradigms.
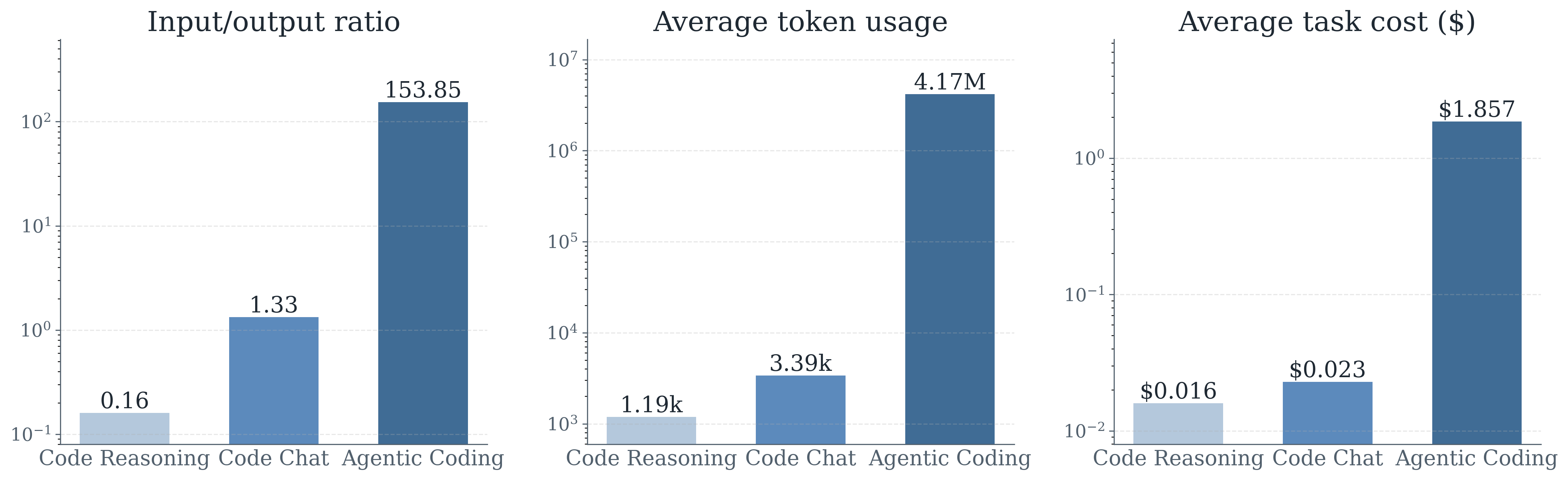
Token consumption across different coding-related tasks.
2) Token usage is highly variable
Across 500 SWE-bench tasks, the mostexpensive instance consumes ~7M more tokens than the cheapest, with high-cost problems showing the largest cross-run variance. Even on the same problem, the most expensive run costs roughly 2× the cheapest across all models, making upfront cost prediction fundamentally difficult.
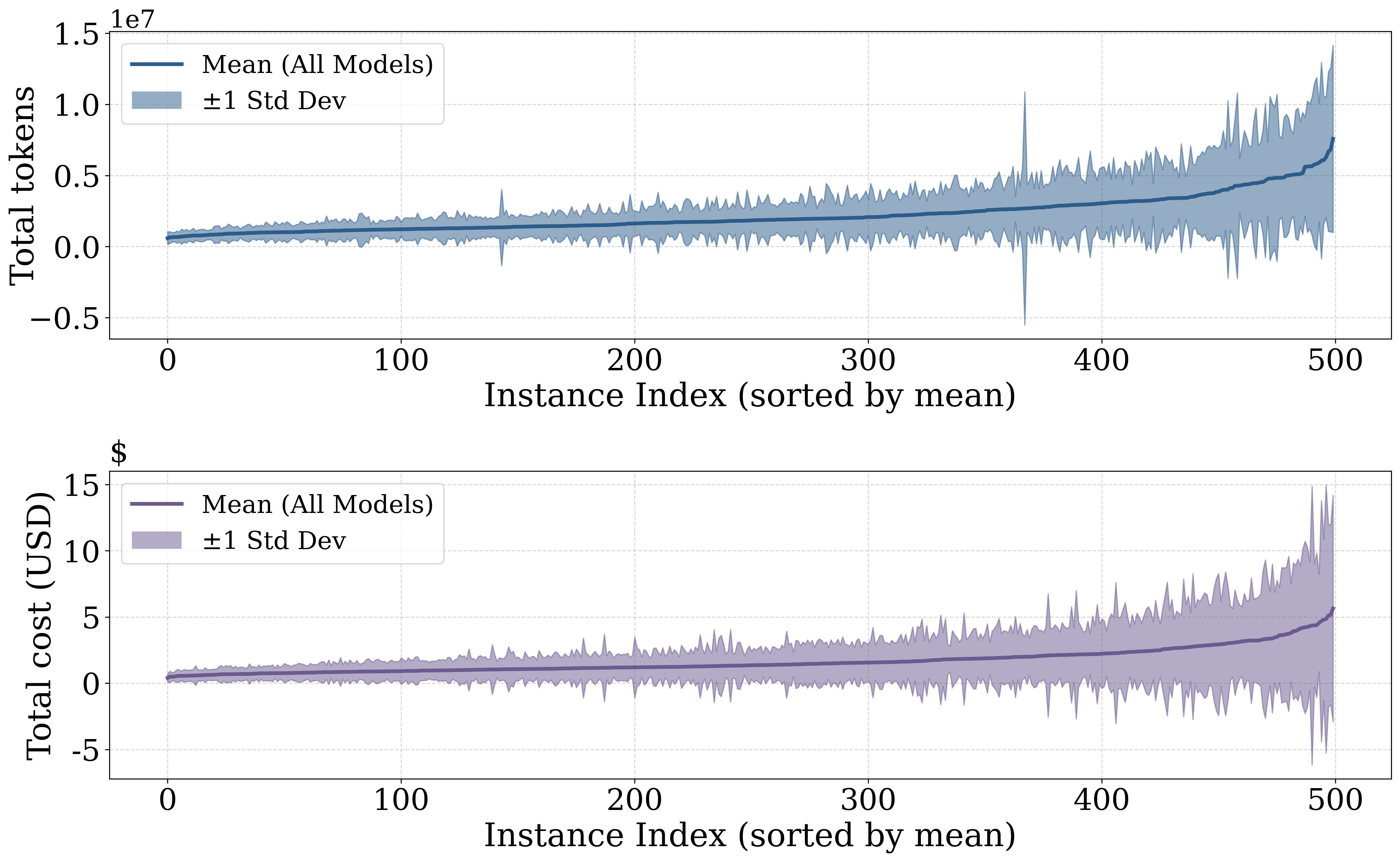
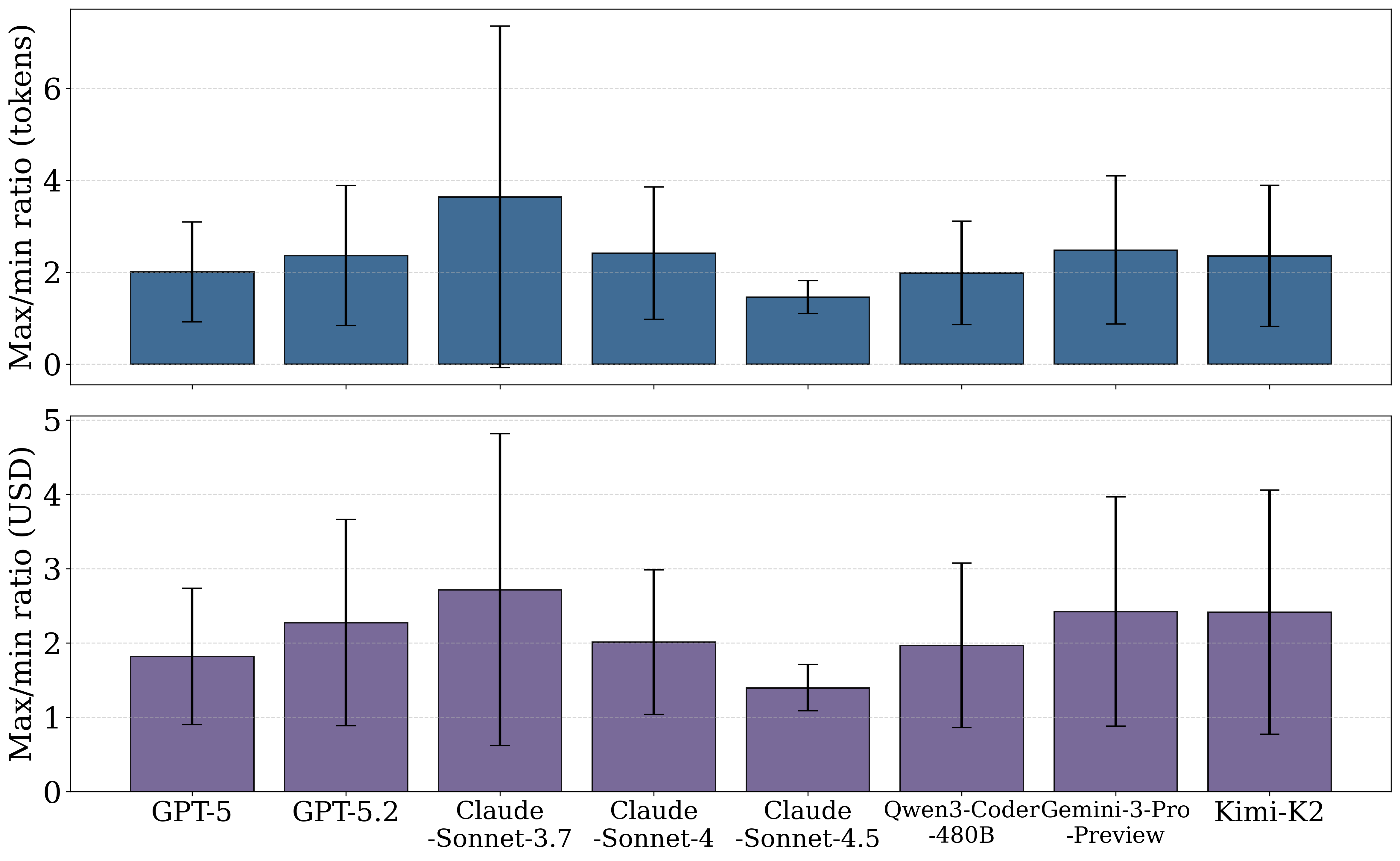
Model-dependent cost differences and large variability across problems and runs.
3) More tokens does not mean better performance
Accuracy peaks at intermediate cost and degrades at higher cost, consistent with an inverse test-time scaling phenomenon: extra computation often reflects inefficient exploration and context bloat rather than better problem solving.
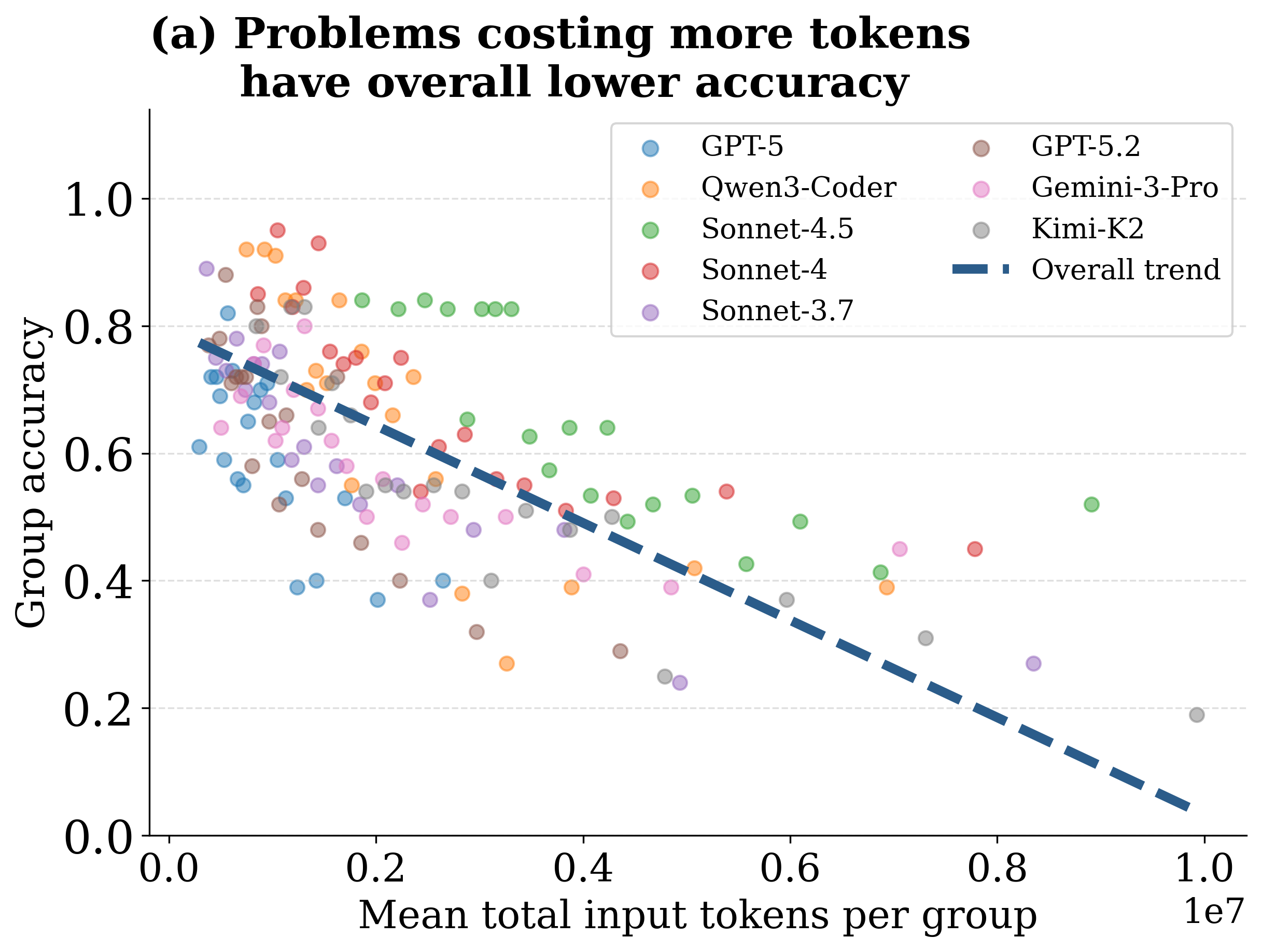
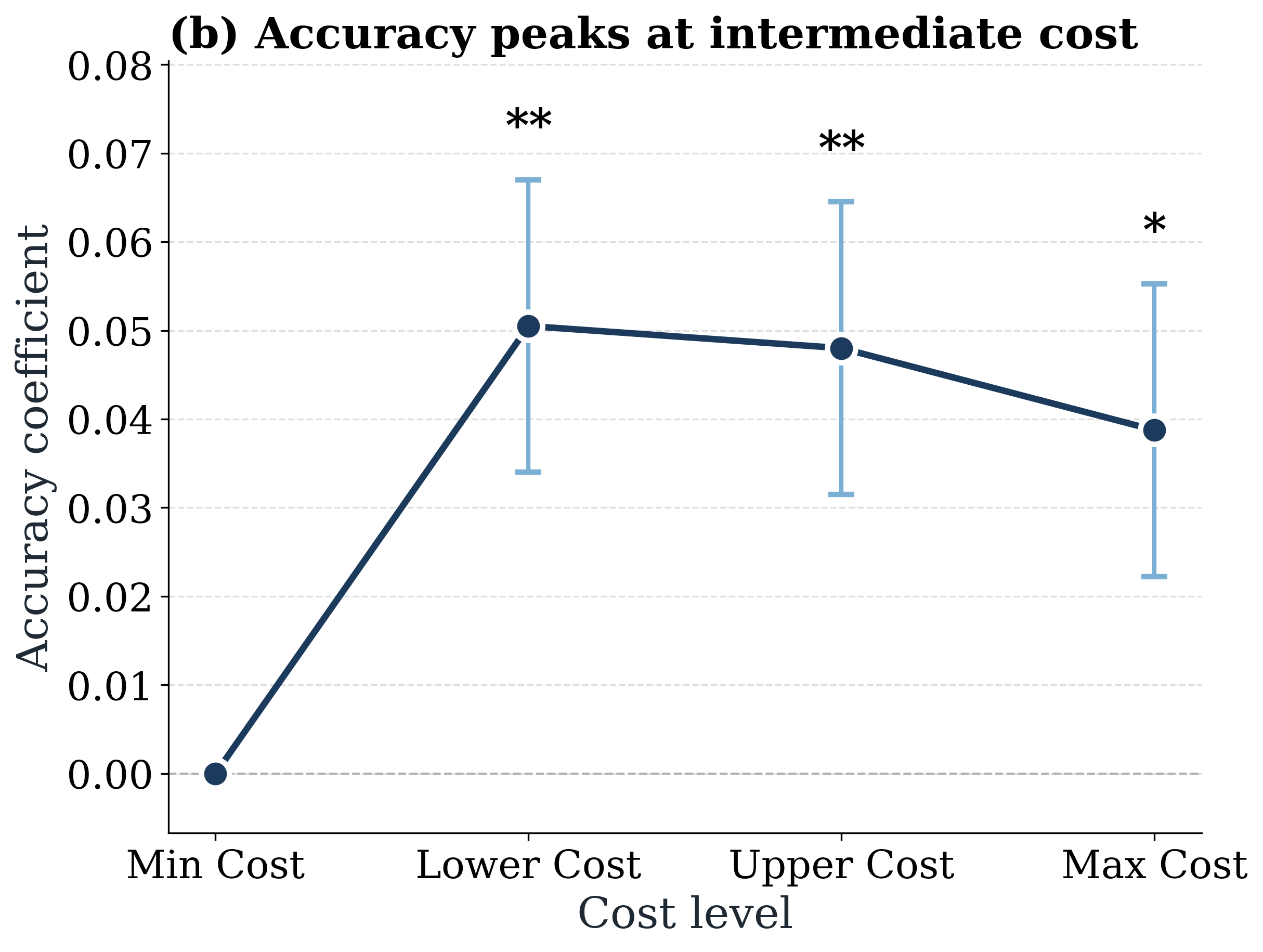
Inverse test-time scaling: higher-cost runs are usually less accurate.
4) Expert-rated task difficulty is a weak predictor of agent token consumption
While token usage rises with human-perceived difficulty on average, the alignment is far from linear (Kendall τ = 0.32), with substantial overlap across difficulty groups: 6.7% of “<15 min” tasks exceed the “>1 hr” mean, and 11.1% of “>1 hr” tasks fall below the “<15 min” mean. This reveals a fundamental gap between human-perceived complexity and the computational effort agents actually expend.
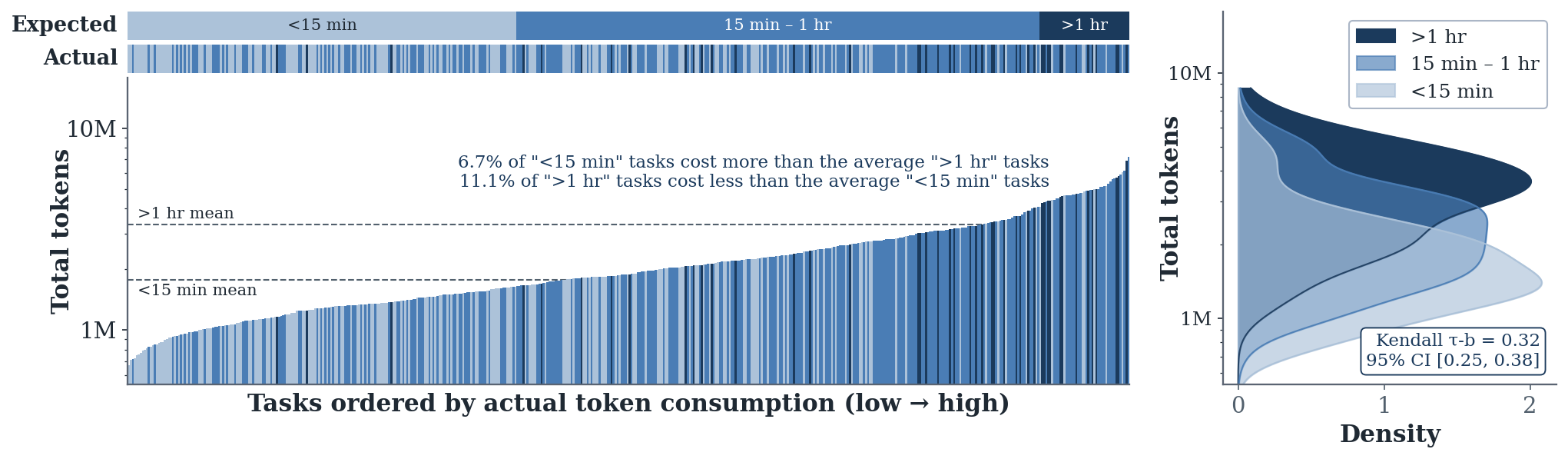
Difficulty labels only weakly align with agent resource expenditure.
5) Backbone models follow distinct token-use patterns
Token efficiency varies substantially across models and reflects model-specific behavior rather than task difficulty. (a) GPT-5 and GPT-5.2 achieve strong accuracy at low cost, while Kimi-K2 stands out with the highest token usage yet lowest accuracy. (b) The relative ranking of token usage across models stays consistent on both the shared success (n=230) and shared failure (n=100) subsets, indicating that token efficiency is an inherent characteristic of the model rather than a property of the task.
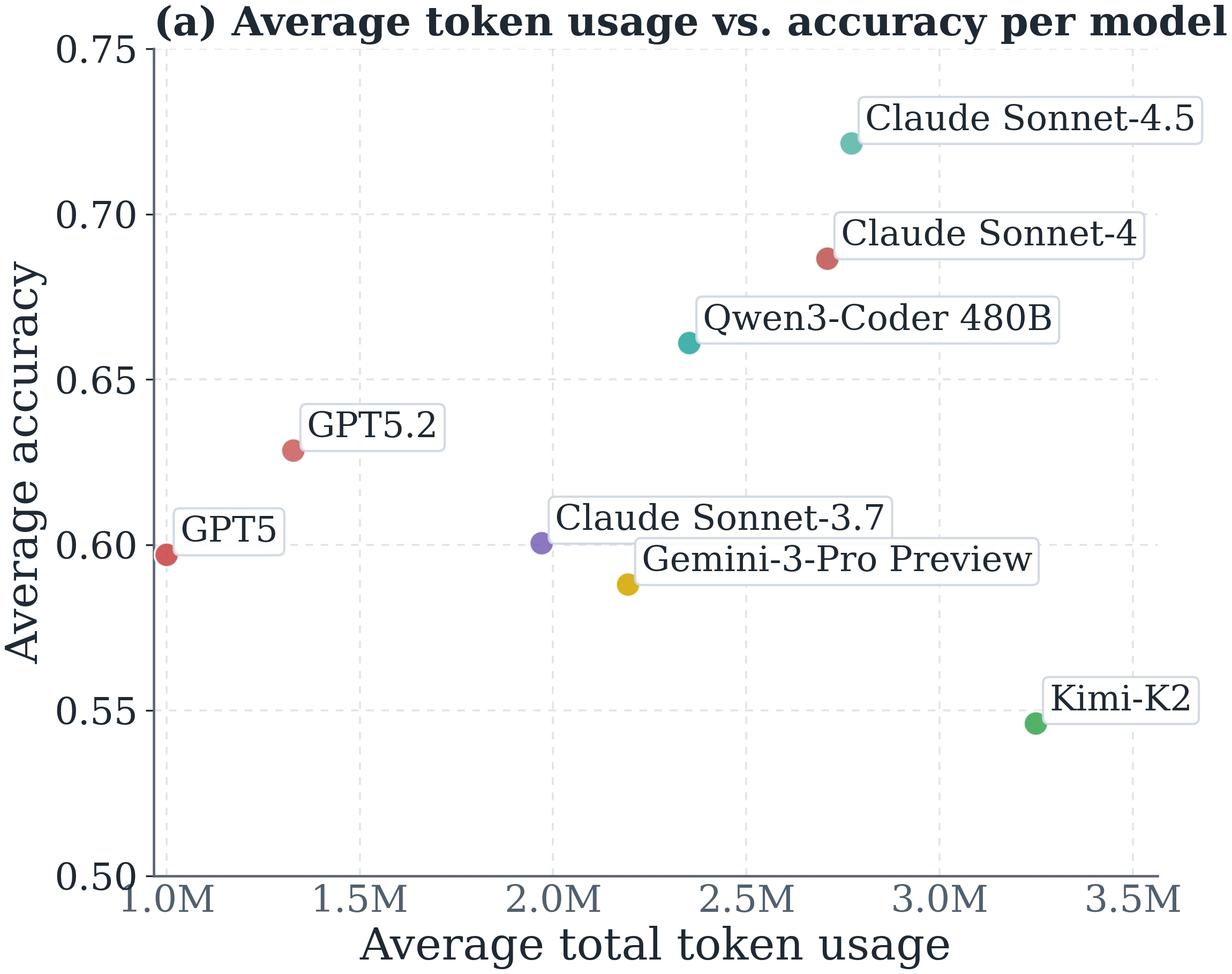
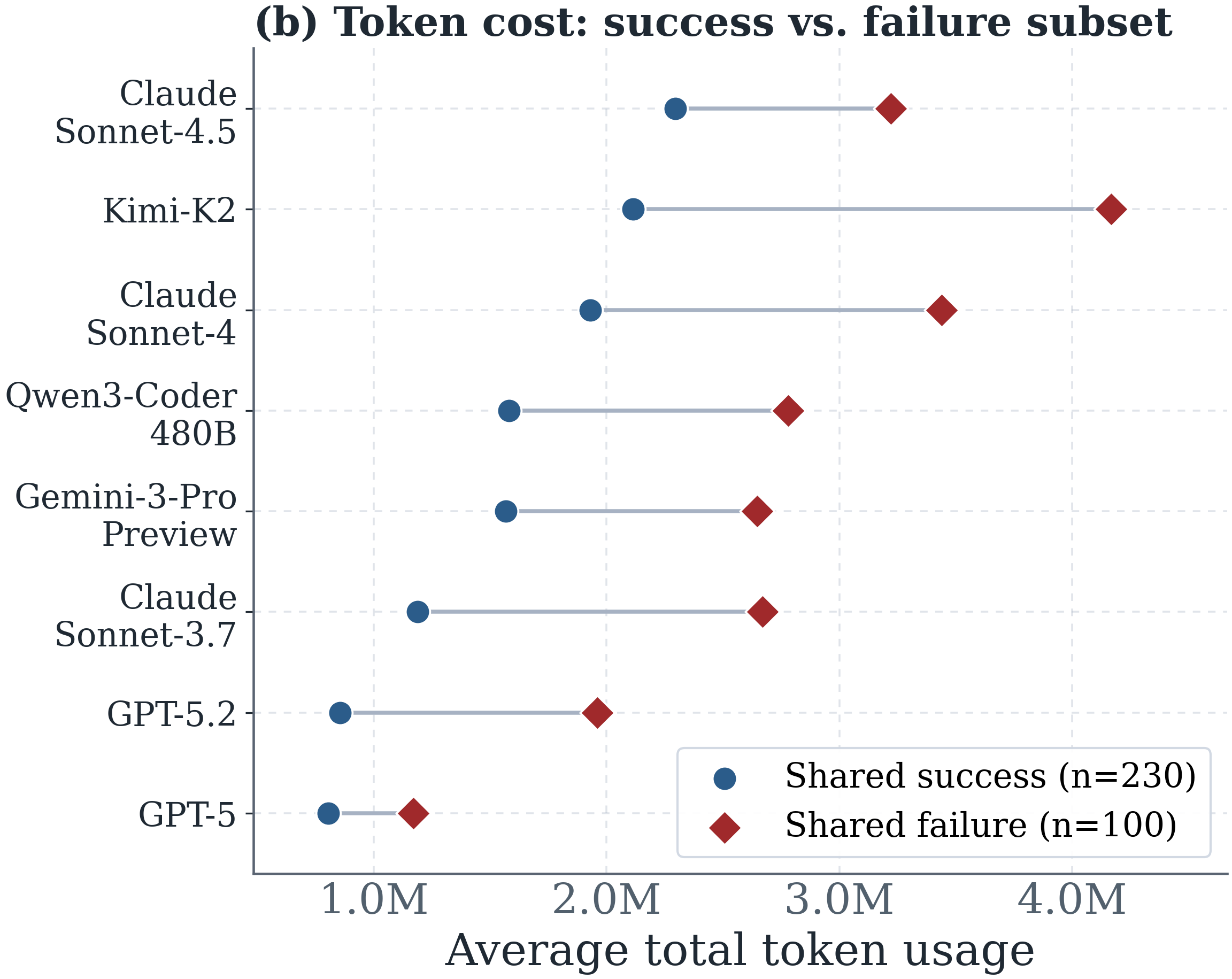
Different backbones show distinct token-consumption profiles and usage-performance tradeoffs.
6) Where tokens go across phases
Cache-read input tokens dominate both raw token volume and dollar cost across all five problem-solving phases, with the Fix and Explore phases incurring the highest costs. Despite output tokens being priced ~80× higher per token, the sheer volume of accumulated context makes cheap-per-token cache reads the largest cost contributor in aggregate.
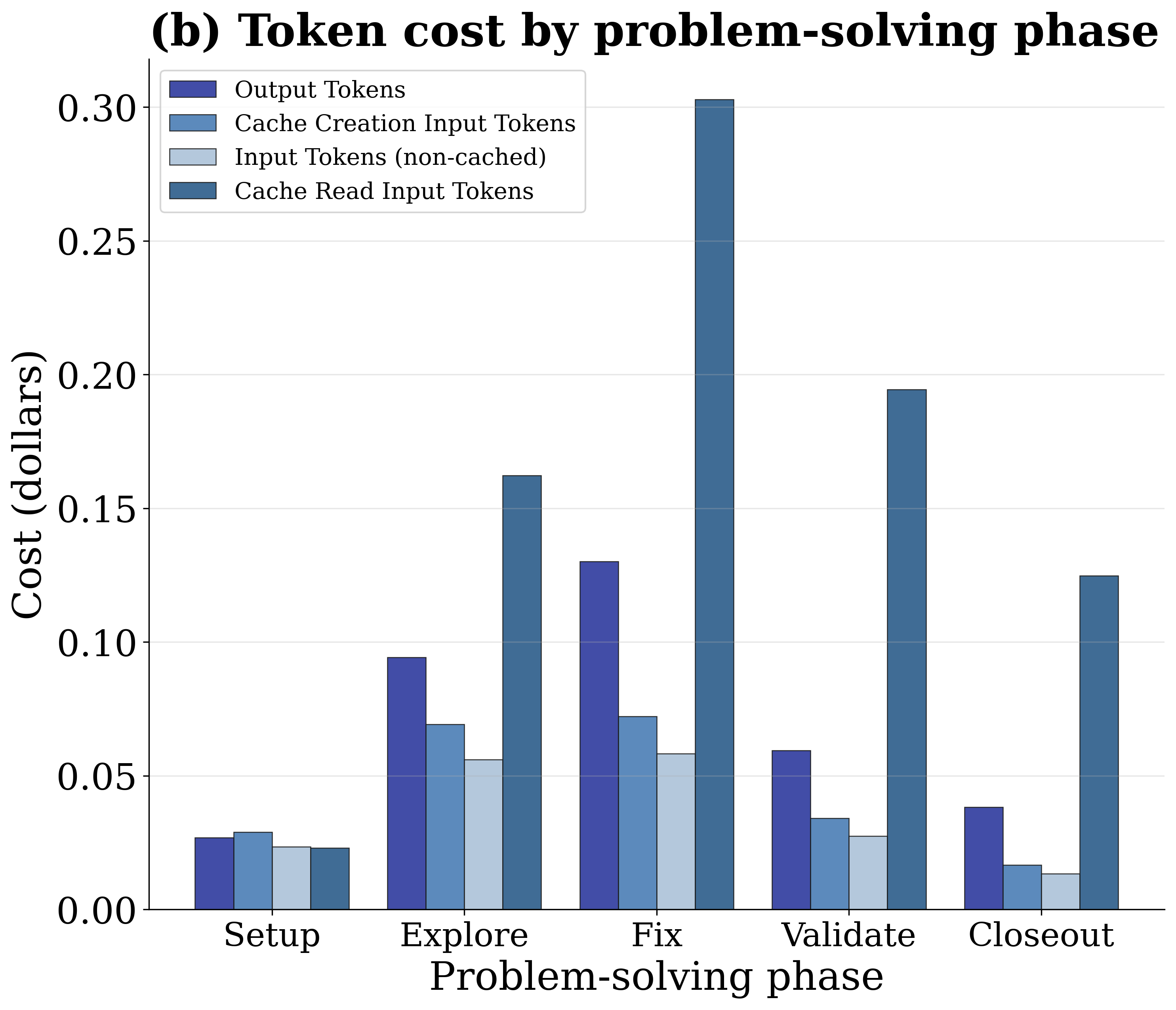
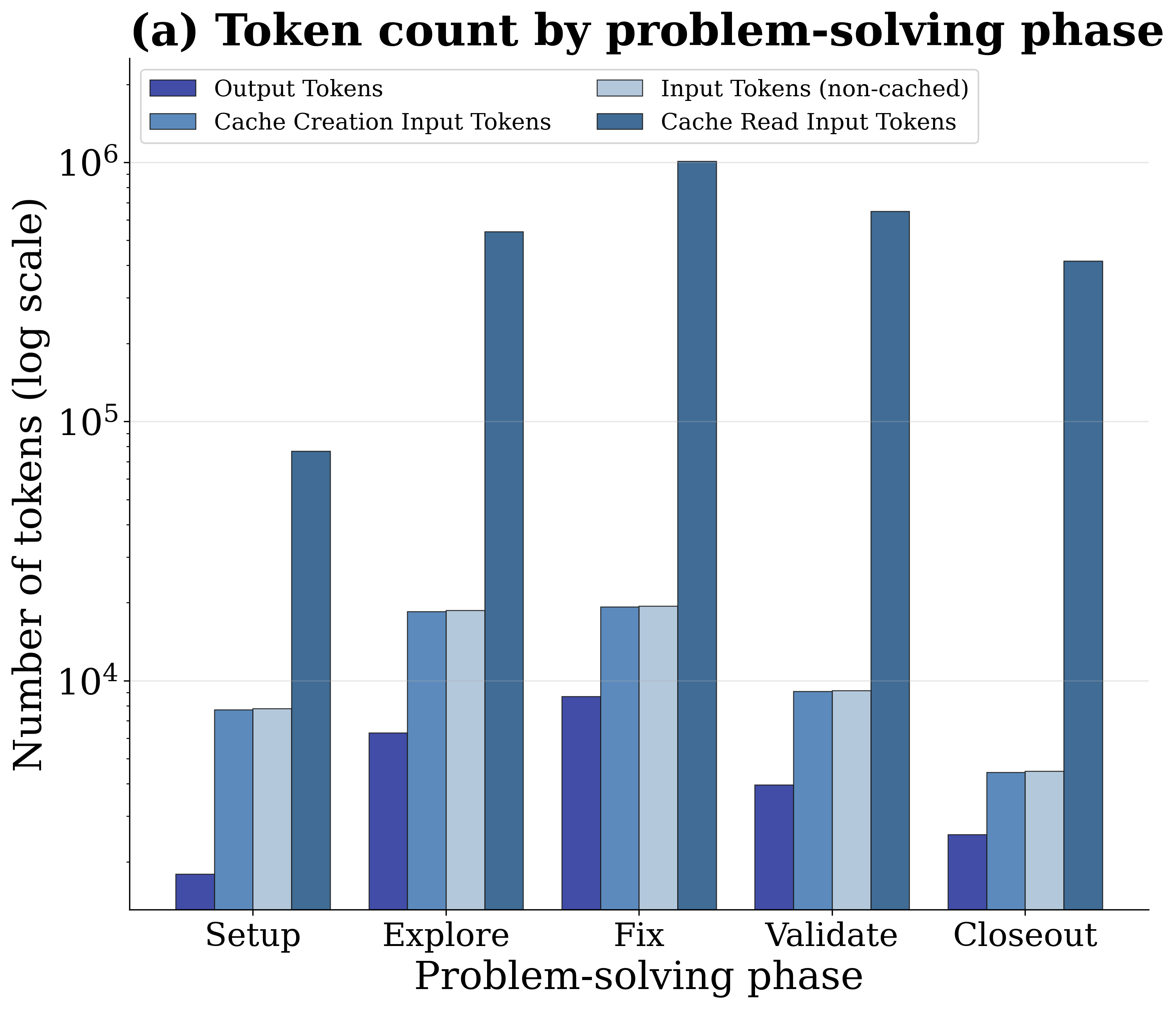
Phase-level token usage and cost dynamics across the trajectory.
7) Self-prediction gives a coarse cost signal
Asking the agent to estimate its own token usage achieves weak-to-moderate correlations with ground truth across models. Output-token prediction tends to be easier than input-token prediction.
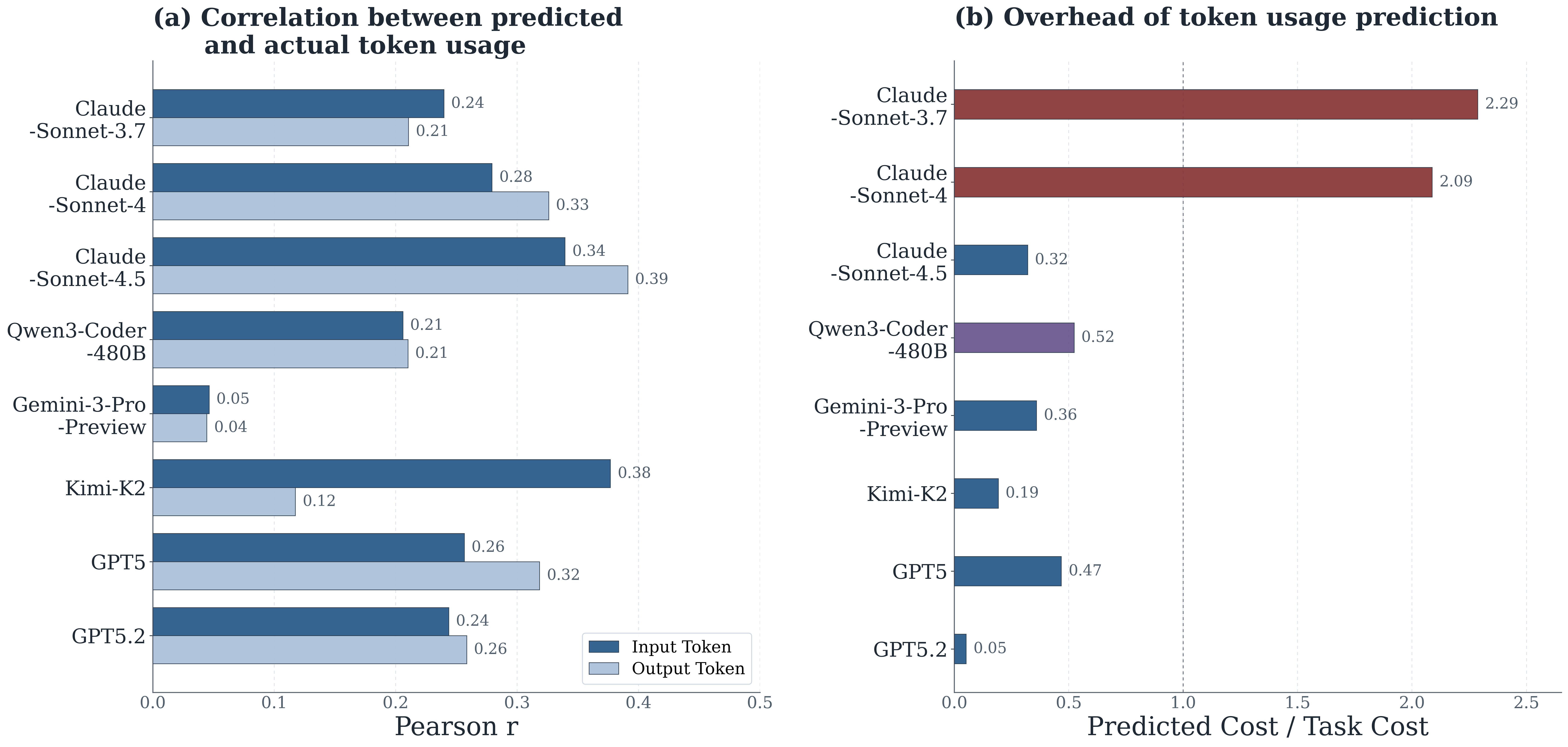
Pearson correlations between predicted and ground-truth token counts, plus relative overhead of self-prediction.
8) Self-prediction is systematically biased downward
Across models, self-predictions consistently underestimate true token usage. The bias is strongest for input tokens, while output-token predictions track the diagonal more closely but still undershoot higher-cost cases.
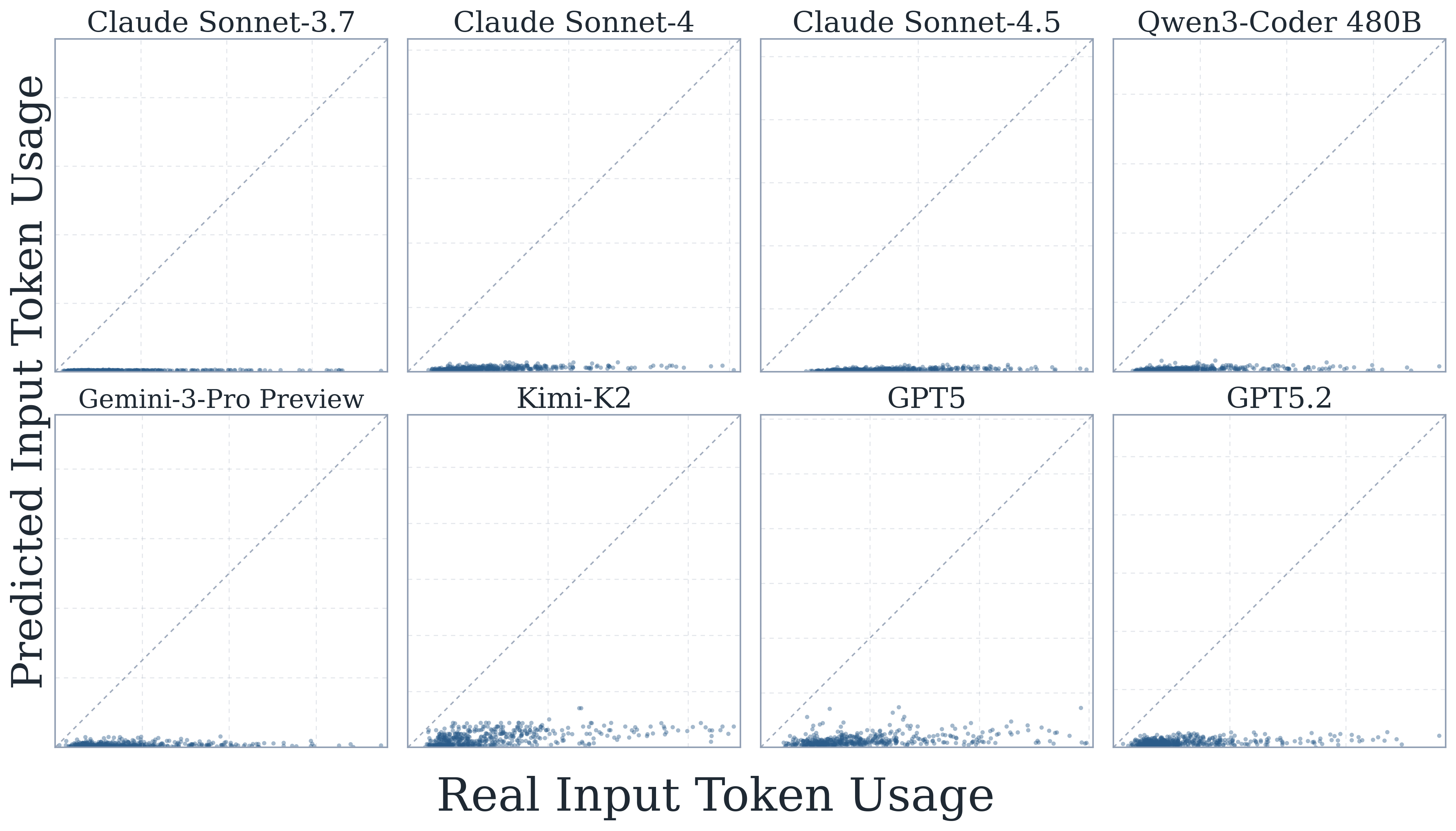
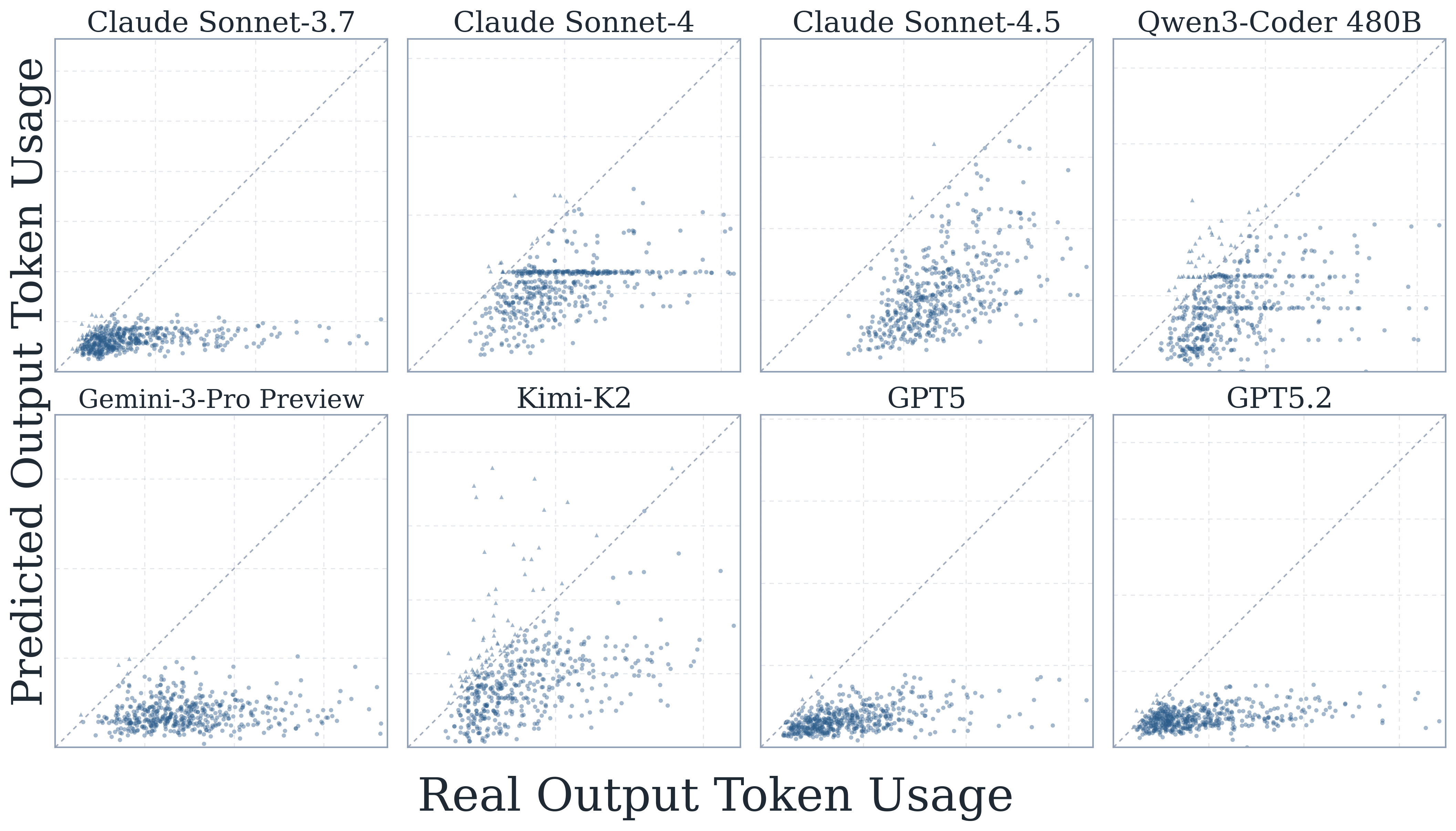
Self-prediction shows a consistent downward bias, especially for input-token estimates.
Human Guessing Leaderboard
Most Accurate Human Predictions
| Rank | Problem ID | Guessed Tokens | Actual Tokens | Guessed Cost ($) | Actual Cost ($) | Token Error % | Cost Error % | Combined Error % |
|---|---|---|---|---|---|---|---|---|
|
No guesses yet. Play the game to see your predictions here! |
||||||||
BibTeX
@article{bai2026tokenconsumption,
title = {How Do Coding Agents Spend Your Money? Analyzing and Predicting Token Consumptions in Agentic Coding Tasks},
author = {Bai, Longju and Huang, Zhemin and Wang, Xingyao and Sun, Jiao and Mihalcea, Rada and Brynjolfsson, Erik and Pentland, Alex and Pei, Jiaxin},
journal = {Preprint},
year = {2026},
url = {http://arxiv.org/abs/2604.22750}
}